Attention is all you need
Attention is All You Need(Transformer模型)
Transformer模型是近5年最有名的NLP模型,它只使用self-attention(自注意力)机制,而非 Convolutional Neural Networks (CNN,卷积神经网络) 或者Recurrent Neural Network( RNN,循环神经网络)。该模型的提出解决了原本在RNN难并行、较长距离的记忆效果不佳的问题。
受限于个人的知识储备并且是第一次读这篇论文,本文只从整个模型的结构和和效果上进行解读,不涉及具体的应用。同时由于是初读这篇文章,解读可能会有偏差与错误,希望大家指正。由于这篇论文太过有名,后期还会反复阅读和理解,这次只是初读后的理解记录。
模型结构
Transformer模型最早被提出是用于解决翻译问题,后来也被用于包括计算机视觉等领域。他的整个模型结构分为两个部分:Encoder(编码器)和Decoder(解码器)。这两个部分又含有四个小的模块。接下来会逐一进行解释。
编码器和解码器
- 大多数的竞争性神经序列传到模型都是利用了编码器和解码器的结构。在本论文中编码器主要是将序列转换成向量形式,解码器则是解析这些向量并输出结果。
- 编码器
编码器分为两个部分:多头自注意力和前馈神经网络。每个部分后面都有一个残差连接和层norm化。在本论文中,作者设定的层数, 维度为512。
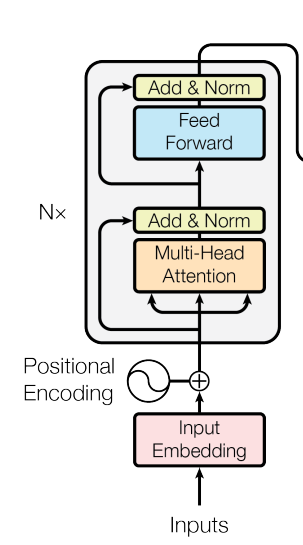
- 解码器
解码器分为三个部分:多头自注意力、前馈神经网络和掩盖的多头自注意力。
解码器和编码器其实没有特别大的差别,基本结构是一样的,解码器只比编码器多了一个Masked(掩盖),主要是为了保证输入t时间是看不到t时间之后的内容,使训练与预测的内容一致。
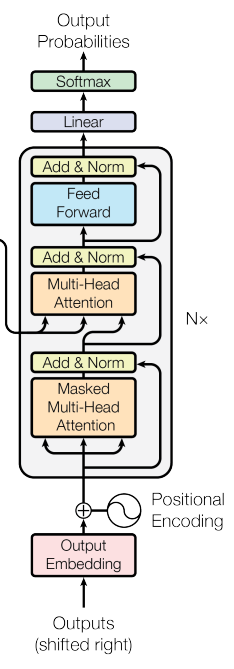
Attention机制
- 本文最重要的机制就是Attention机制。虽然这种机制并不是作者第一个提出,但是作者利用该机制的特性创造的Transformer模型解决了RNN中运算难并行,长期记忆易丢失的问题,是NLP近五年最重要的模型。
- 什么是注意力机制?
注意力机制本质就是要计算权重,最终实现加权值的输出。具体实现上,有三个参数,query、key、value。先比较query和key的相似性,然后根据query 与 key 的相性去找到最合适的 value,最终将加权好的value输出。 - Scaled Dot-Product Attention(大规模叉乘注意力)
注意力机制中分为两类:Dot-Product Attention(叉乘注意力)与Addictive Attention(加型注意力),本论文使用的是叉乘注意力,具体操作有如下四步- query和key叉乘
- 除以
- 作用softmax函数得到权重
- 权重乘value得到最终的attention输出
Tip:
- 为什么选择叉乘注意力?
叉乘注意力相比于加型注意力,在矩阵运算中更快,更高效。 - 为什么要除以 ?
在较小情况下除不除都一样,但是当较大时,做叉乘后值与值的相对差距比较大,用softmax作用后大的值更加接近1,小的值更加接近0,值向两端靠,梯度下降的步长会变小,运算量会增大。
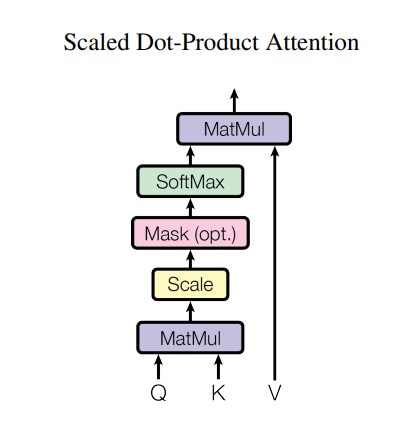
- 多头注意力机制
上述的大规模叉乘注意力包含于多头注意力机制之中。具体的操作是先将query、key、value投影到低维h次,再利用并行方法对这些内容作用叉乘注意力,输出然后再投影回去。
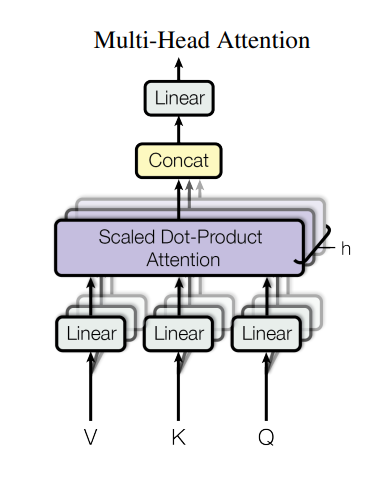
- Attention机制在模型中的具体应用
- 编码器和解码器连接的attention
此处的注意力连接了编码器和解码器,其中value和key来自于编码器的最终输出,而query则来自下一个解码器的带掩码的多头注意力模块。 - 编码器中的attention
编码器中的attention模块里的key、value、query来自同一个地方,这里没有带掩盖的多头注意力机制。说明数据是可以影响之前的数据。 - 解码器中的attention
解码器中的attention含掩盖的多头注意力机制,该机制主要是为了保证输入t时间是看不到t时间之后的内容,使训练与预测的内容一致。
如何设置掩盖的多头注意力机制?
attention会将所有的序列一次性都输出,而掩盖再试将不需要的值设成负无穷。此处是不能放0的,应为之后要作用softmax函数,置0会导致错误。
- 编码器和解码器连接的attention
前馈神经网络
前馈神经网络是包含在编码器和解码器中的,紧跟在attention模块之后。其本质就是带隐藏层的多层感知机。不同之处在于他对于每一个词都使用作用了一次MLP。其实就是含有一个隐藏层,然后输入后隐藏层将维度扩大4倍,最后在投影到原来的维数。外部的输出是,内部的隐藏层
Embedding和Softmax
Embedding就是将每一个词转换成一个词向量,维数是512.
在这里每一个Embedding权重都乘了一个。原因是对于每一个词的学习在较大维数时都会接近1,如果乘了,就不会有这种现象。
时序编译
在整个模型中,模型计算输出的值是权重,这个权重代表的是你输出的值与之前值的一个距离,无关乎这个值在序列中的位置,这显然是有问题的,机器翻译后的结果必须是按照一定的语序的,不能是乱的单词,所以要进行一个时序的编译。Attention是在输入时加入一个时序信息确定具体的顺序。具体公式如下:
![]()
复杂度分析
上图分析了四个模型的三种复杂度,分别为每层的复杂度、序列操作复杂度和最大路径长度由上图可以得到以下几点:
- 在每层复杂度上,在d较大时自注意力和RNN其实差不多,但是在序列操作上自注意力比RNN要小很多,最大路径长度也要小。
- 卷积的每层复杂度和RNN差不多,但是卷积的序列操作数少,并行度更高。
- 受限制的attention是将query只和最近的r个邻居进行运算,减少了每层的复杂度。但是这种操作在较长的距离上要走的步长更长,所以损失了最大路径长度的复杂度。
这里总体上来看attention的复杂度是要小于其他模型的,但是并不是说attention一定比其他的模型好,因为attention做了更少的假设,所以数据规模要更大,模型要更大,还是有牺牲的。
参数调节
Transformer模型和其他模型不太一样,该模型需要调整的参数很少。
- 学习率
计算公式:
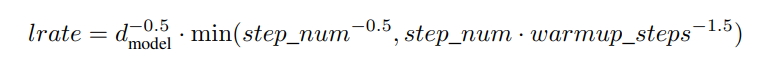
可以看到该模型的学习率不是一成不变的。其中学习率和模型宽度的-0.5次方相关,再乘一个系数。其中warmup_step设置为4000。 - 正则化项
- Dropout 设置为0.1。dropout就是要丢弃的东西,该模型基本上在每一带权重的乘上都设置了的dropout。
- softmax的阈值设置为0.1。意思就是说只要10%的正确就可以了。
 wechat
wechat alipay
alipay








