BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
BERT(Bidirectional Encoder Representations from Transformer)是近几年最重要的NLP的模型,正是由于该模型的建立,使得NLP领域也能够使用到预训练的通用大模型,使得较小的问题得到了更好的解决,极大地推动了NLP的发展。
BERT模型是基于Transformer模型所设计的,他的设计思路是依赖同时期的两个模型ELMo和GPT,BERT是融合了ELMo和GPT的优点而创建。ELMo考虑到了序列前后的信息来预测中间内容,但是架构是比较老的RNN;GPT使用了Transformer,但是他只是考虑了左边的信息,利用之前的序列预测之后内容。因此BERT使用Transformer模型实现了双向的预测,可以说BERT的成功是站在巨人的肩膀上的。
如果读过Transformer那一篇论文的话可以知道,整个Transformer模型是有encoder和decoder两个部分组成的,decoder比encoder多了一个带掩盖的多头自注意力模块。这背后的原因是attention机制是可以实现整个序列的预测,但是在机器翻译领域,你不能用后面的信息来预测之前的信息,所以需要添加带掩盖的多头自注意力模块。但BERT解决的问题类似于缺词填空,可以使用整个序列的信息,所以BERT这个模型使用到的是Transformer的encoder部分模块。
BERT整体思路其实比较简单,他的关键词是: 双向、预训练、深的。这是他最大的优点,也是他最为成功的地方。不过也正是因为双向的原因,他不适合做由前到后的预测。
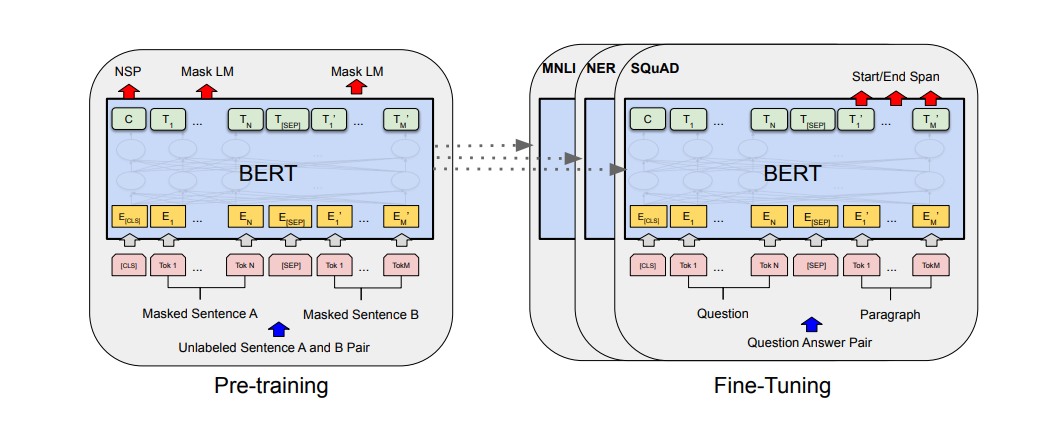
模型架构
BERT完全基于Transformer构建,他使用了多层Transformer的编码器,输入的Embedding通过一层层的Encoder进行编码转换,再连接到不同的下游任务。
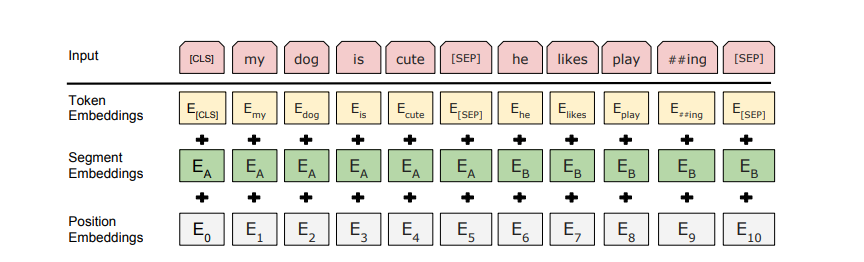
BERT采用 并行 输入的方式输入模型,输入效率更高。他的切词方法主要使用了两个标记词: [CLS] 用于每个输入序列之前; [SEP] 用于每一句话之间的分割。他的切词策略是将出现概率小的词切成词根,这样可以保证以较小的词根文本进行训练。在输入层主要有三个Embedding层,分别是Token Embedding(词元对应向量),Segment Embedding(词元所处句子),Position Embedding(词元在序列中的位置)。具体实现如下图:
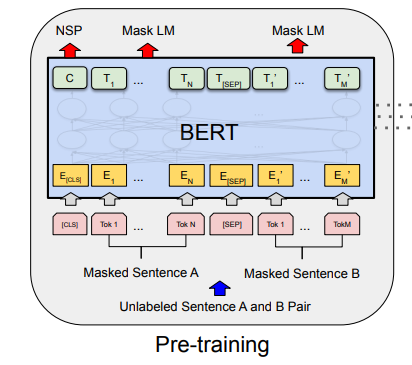
BERT模型主要有两个步骤:预训练和微调。所谓的预训练就是在没有标记的大数据集上进行无监督的聚类学习,而微调是完全继承大模型的参数,然后在特定任务下使用标注好的数据进行训练以此来微调参数。
预训练
BERT的预训练包含两个任务,一个是Masked Language Model(MLM),另一个是Next Sentence Prediction(NSP)
MLM
上文已经提到,BERT解决的是缺词填空的问题。为了训练模型,我们就需要有空缺需要我们去填。论文对于数据集上15%的数据进行了挖空。但是这种挖空不是简单的掩盖掉,而是又按照8-1-1的占比,进行不同的处理,80%加掩盖,10%加噪(使用一个毫不相干的词替换),10%的词保持不变。
NSP
考察句子是否是有顺序关系的,本任务中采用50%的正例,50%的反例,使得模型能够理解句子之间的关系。
整个预训练模块可以用如下的图表示:
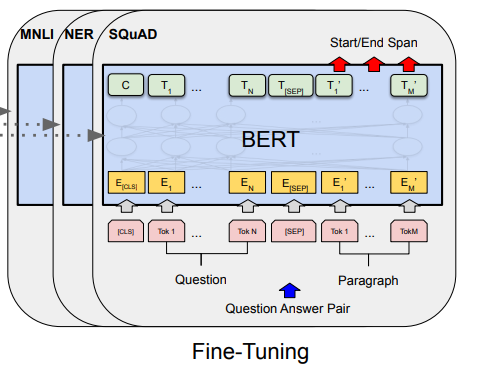
微调
微调的意思就是针对具体的自然语言处理问题,使用标记好的文本数据集来对已经预训练好的通用BERT模型进行参数的微调,以达到更加好的模型效果。
对于fine-tuning来说,因为BERT是基于Transformer的,所以要调整的参数很少,只有batch_size, lr, epochs需要调整。
BERT和GPT的比较
- BERT的训练语料更大,大概是GPT的3倍;
- GPT仅在微调时使用[SEP]和[CLS]符号,而BERT在预训练和Fine-tuning阶段都使用[SEP]和[CLS]符号;
- BERT训练的batch_size大约是GPT的4倍;
- GPT使用固定学习率lr=5e-5,BERT根据特定任务选择lr;
本文暂时更新到这,后续还会更新BERT一文的实验、效果以及附录的内容
 wechat
wechat alipay
alipay








