查找
查找
之前的内容已经介绍了关于线性、树形和网状的数据结构,本章介绍数据结构的重要操作:查找
基本概念
- 数据表:数据元素的有限集合
- 关键字:在数据表中可以最为查找排序的数据元素
- 查找:根据给定数据元素查找其在数据表中的位置
- 静态查找表和动态查找表:查找的数据不在数据表中,根据之后是否会将该元素插入到数据表中来判断是动态查找表还是静态查找表
- 查找效率:衡量指标,平均查找长度(ASL),含义是关键字比较次数的数学期望。
- 装载因子:数据表中装载元素的情况,计算公式
顺序表的查找
顺序表的查找有两类:顺序查找和折半查找
顺序查找:
n个元素的表从头查找到尾,边查找边比较
在等概率的情况下,平均查找长度为
- 如果概率不同,可以从概率较高的一端开始查找,以提高查找效率
- 同样,如果是按照链式存储的方式存储数据表的,查找方式和顺序表是一致的。
- 如果顺序表有序,也可以进一步提升查找效率
优点:查找思想简单
缺点:查找的长度较长,在n较大时效率较低
有序表的折半查找
此处强调前提要求必须是有序
- 折半查找分为三步
- 如果区间长度小于1,查找失败,否者继续以下操作
- 求出区间中间点的下标
- 将区间中间的数据元素的关键字和查找的数据关键字进行比较
- elem[mid]==key,查找成功
- elem[mid]< key 在左区间进行折半查找
- elem[mid]> key 在右区间进行折半查找
template <class ElemType, class KeyType> //递归实现折半查找 |
template <class ElemType> //迭代实现折半查找 |
无论是递归还是迭代实现折半查找,内容其实是类似的。
2. 折半查找性能分析
==折半查找的性能分析是通过构建二叉查找树来进行的==
构造方式(递归构造):
* n=0,空树
* n<>0,每一层的父亲节点是查找区间的中间元素 mid=(n-1)/2
* 扩充的二叉查找树,将所有结点的空指针指向空
一般地,折半查找的比较次数为
==折半查找的平均查找长度为 ==
3. 折半查找的变形
* 斐波那契查找:折半查找是每次把区间分成等长的两块,而斐波那契查找是将区间分为斐波那契长度的块,平均性能比折半查找好,但是平均查找长度是一样的。
* 插值查找:插值查找的思想和折半查找一样,只是求中点的公式不同
$$mid=low+1+\frac{k-elem[low]}{elem[high]-elem[low]}*(high-low-1) $$
索引顺序表和倒排表查找
索引查找的方式解决的是n比较大的情况下,顺序查找效率较低,内存不够的问题。
索引顺序表
- 基本概念
索引顺序表由主表和索引表组成。
一个索引项对应数据表中一个元素时的索引结构叫做稠密索引(完全索引)。
当完全索引表中关键字分块有序存放(n个索引项分为m个块(子表)。可以为完全索引表建立一个二级索引表,在二级索引表中一个索引项对应完全索引表中的一个子表,它记录了相应子表中最大关键字以及该子表在数据区中的起始位置,这种索引被称为二级索引。
这几个概念之间的关系图如下:
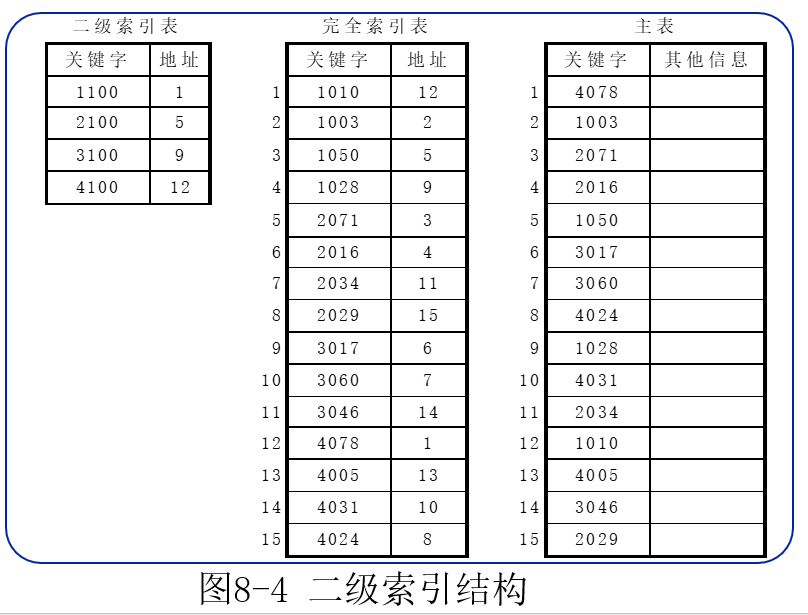
- 二级索引查找过程
先在二级索引中查找(确定字表序号)->在第i个字表中查找->找到则返回值,找不到则失败。 - 查找性能分析
索引顺序查找平均长度分为两个部分,二级索引查找长度和字表查找长度。
如果使用顺序查找方式,则平均查找长度为:如果使用折半查找方式,则平均查找长度为:
倒排索引表
如果把一些在查找时经常用到的属性设定为次关键字,并以每一个属性作为次关键字建立次索引表,称为倒排索引表。简言之,就是建立一个关于次关键字的表,使得查找时更加方便。
链式倒排索引表结构图如下:
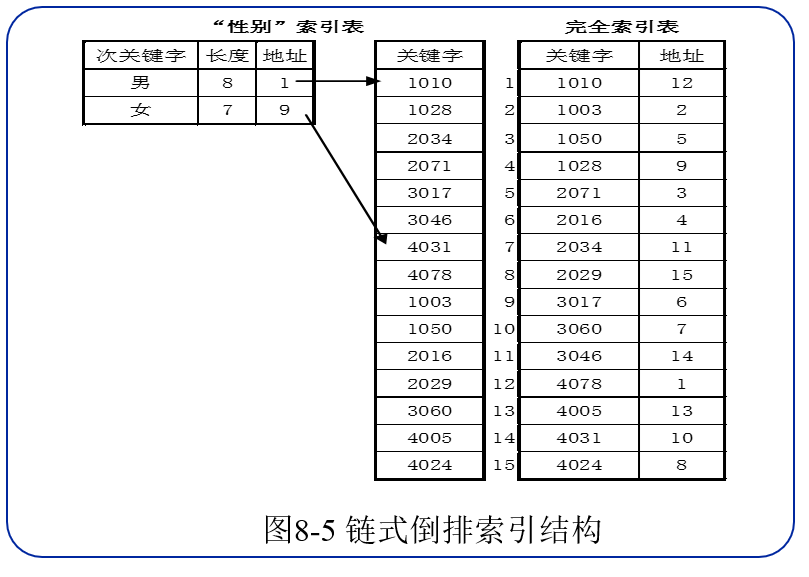
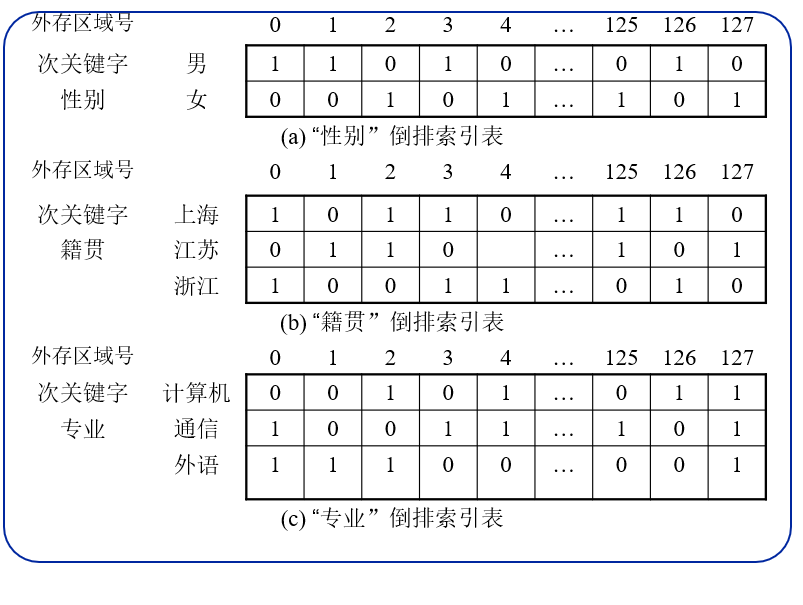
单元式倒排索引表例子:
二叉排序树
概念
二叉排序树是一棵中序排列为顺序的树,根节点的左子树所有结点小于根节点,右子树所有结点大于根节点,左右子树都是二叉排序树(递归)。
二叉排序树的查找
查找方式就是从根节点开始比较要查找的关键字的值与结点关键值的值的大小,不断向下查找直至找到结点。代码实现如下:
template <class ElemType> |
二叉排序树的插入
要构建一棵二叉排序树,必须有插入结点的操作,二叉排序树的插入方法就是从根节点开始不断比较大小,直到找到可以存放新结点的叶子位置停止。代码实现如下:
template <class ElemType> |
有了插入操作,我们就可以构建二叉排序树。
二叉排序树的删除
有结点插入就一定有结点删除,删除结点要分情况来看:
- 如果被删除的元素是叶子,则只需将其双亲指向它的指针置空,再释放该数据元素的存储空间即可;
- 如果被删除的元素只有单子树,则可以用它的孩子顶替它的位置,再释放该数据元素的存储空间即可;
- 如果被删除的元素左、右子树都存在,则:
- 在左(右)子树中寻找最大(小)的元素 (中序遍历中最后一个(第一个)被访问的元素)x
- 用x的值代替被删除元素的值
- 删除数据元素x(x没有右(左)子树)
代码实现如下:
template <class ElemType>void BinarySortTree<ElemType>::Delete(BinTreeNode<ElemType> *&p){ |
二叉排序树查找性能分析
二叉排序树是完全二叉树时,其平均查找性能最佳为 ,与有序表的折半查找相同。当二叉排序树退化为单分支树时,二叉排序树的平均查找性能最差为,与顺序表平均查找长度相同。
平衡二叉树
根据二叉排序树的查找性能分析可以看出来,并不是所有的二叉排序树都具备较好的查找性能,而为了提高二叉排序树的查找效率,我们引入了平衡二叉树的概念(本质还是一棵二叉排序树)。这一部分内容主要分为三个部分:定义、平衡旋转(二叉排序如何变为平衡二叉)和平衡二叉的插入删除。
平衡二叉树的定义和概念
平衡因子:树中结点右子树的高度减去左子树的高度所得的高度差
平衡二叉树的任一结点的平衡因子只能取-1、0和1,如果出现平衡因子绝对值大于1的情况,则树不平衡。
只要n个结点的树高度保持在,平均查找长度就可以保证在
==平衡旋转==
插入删除结点可能导致平衡二叉树不平衡,为了保证平衡性,就有了平衡旋转的操作。对于保证平衡二叉树的平衡性来说,只要针对性地对失衡的最小子树进行平衡旋转即可。平衡操作一共有四种LL,RR,LR,RL旋转。
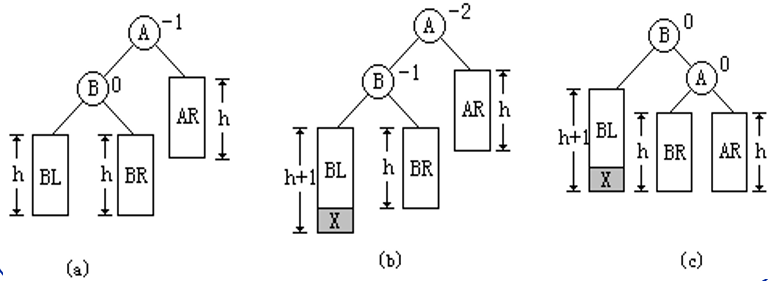
LL旋转
在A的左(L)孩子B的左(L)子树上插入新结点,使A的平衡因子由-1变成-2,则进行LL平衡旋转(左边的左边插结点)
从A沿插入路径连续取2个结点A和B,以B为旋转轴,将结点A顺时针向下旋转成为B的右孩子,结点B代替原来结点A的位置,结点B原来的右孩子作为结点A的左孩子。(左边变根节点,原根节点加左右子树为右子树)
操作图如下:
RR旋转
在A的右®孩子B的右®子树上插入新结点,使A的平衡因子由1变成2,则需要进行RR平衡旋转(右边的右边插结点)
沿插入路径连续取2个结点A和B,以B为旋转轴,将A逆时针向下旋转成为B的左孩子,B代替原来A的位置,B原来的左孩子成为A的右孩子。(右边变根节点,原结点加右左子树为左子树)
操作图如下:
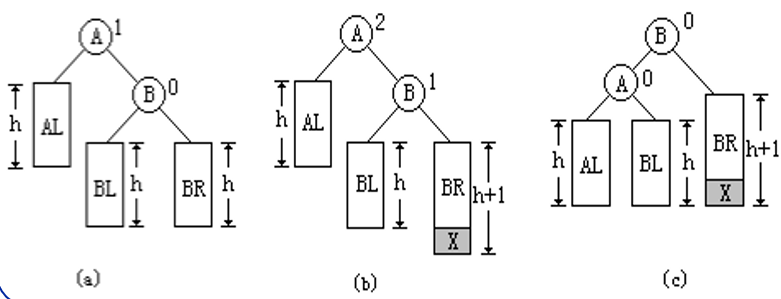
LR旋转
在A的左(L)孩子B的右®子树上插入新结点,使A的平衡因子由-1变成-2,则需要进行LR平衡旋转(左边的右边插入结点)
先将A的左孩子B的右孩子C向逆时针方向旋转代替B的位置,再以结点C为旋转轴,将结点A向顺时针方向旋转成为C的右孩子,结点C代替原来结点A的位置,结点C原来的左孩子转为结点B的右孩子,结点C原来的右孩子转为结点A的左孩子。(C替代根节点,C的左右子树分配给A,B的左右子树)
操作图如下:
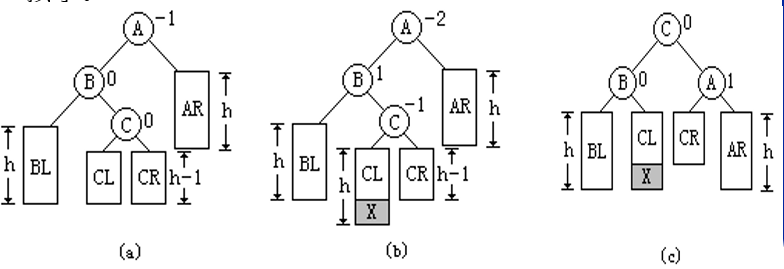
RL旋转
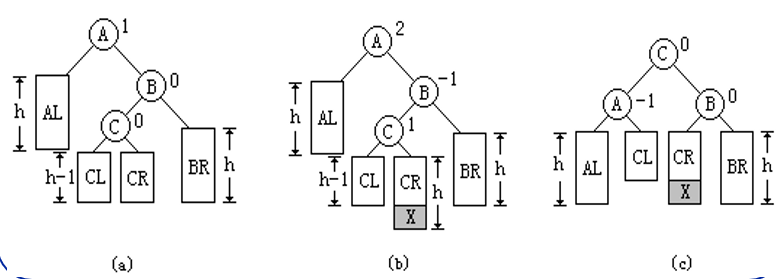
在A的右®孩子B的左(L)子树上插入新结点,使A的平衡因子由1变成2,则需要进行RL平衡旋转(右边的左边插入结点)
先将A的右孩子B的左孩子C向顺时针方向旋转代替B的位置,再以C为旋转轴,将A向逆时针方向旋转成为C的左孩子,结点C代替原来结点A的位置,结点C原来的左孩子转为结点A的右孩子,结点C原来的右孩子转为结点B的左孩子。(C替代根节点,C的左右子树分配给A,B的右左子树)
操作图如下:
平衡二叉树的插入删除
插入
总体思路:按照排序原则找到要插入的位置,插入后观察是否平衡,不平衡进行平衡旋转。
具体操作:
- 在查找结点x的插入位置的过程中,记下从根结点到插入位置的路径上离插入位置最近的且平衡因子绝对值为1的结点,并令指针a指向该结点;如果此路径上不存在平衡因子绝对值为1的结点,则指针a指向根结点。
- 对于从a结点到x结点的路径上的每一个结点(不包括结点x),根据结点中关键字和x的大小比较修改结点的平衡因子。如果结点关键字大于x,则结点平衡因子减1;否则结点平衡因子加1。(重新计算平衡因子)
- 如果结点a的平衡因子绝对值为2,则表示二叉排序树失去平衡,再根据结点a及其左右孩子的平衡因子值来确定平衡旋转的类型。
==删除==
删除结点时,如果平衡因子绝对值变为大于1的情况,就要进行树的缩短。具体操作如下:
- 如果被删结点x有左、右孩子,首先查找x在中序下的直接前驱y(或直接后继),再把y的内容传送给结点x,再删除结点y(y最多有一个孩子)。
- 对于删除最多有一个孩子的结点x,可以简单地把x的双亲结点中原来指向x的指针改为指到x的孩子结点。如果结点x没有孩子,则其双亲结点的相应指针置为空。
- 对于从结点x的双亲到根结点的路径上的每一个结点p,当布尔变量shorter的值为true时,根据以下三种不同的情况继续处理,直到布尔变量shorter的值为false时,整个删除算法结束。
- 情况一,当p的平衡因子=0,若其左子树或右子树被缩短(shorter的值为true),则它的平衡因子改为1或-1,由于此时以结点p为根的子树高度未缩短,故shorter变为false。
- 情况二,p的平衡因子≠0,且其较高的子树被缩短,则p的平衡因子改为0。由于此时以结点p为根的子树高度被缩短,所以shorter仍为true。
- 结点p的平衡因子不为0,且较矮的子树又被缩短,则在结点p发生不平衡。此时,将进行平衡化旋转来恢复平衡。令结点p的较高子树的根结点为q,则根据结点p和q的平衡因子值,有如下三种平衡化操作。
- 如果q的平衡因子为0,一个单旋转就可恢复p的平衡,由于旋转后被处理子树的高度没有缩短,所以置shorter的值为false。
- 如果q与p的平衡因子相同,一个单旋转就可恢复p的平衡。由于此时被处理子树的高度被缩短,故shorter的值仍为true。最后,结点p和q的平衡因子均改为0。
- 如果p与q的平衡因子的符号相反,则需要执行一个双旋转来恢复平衡,先围绕q转、再围绕p转。由于此时处理子树的高度被缩短,所以shorter的值仍为true,新的根结点的平衡因子置为0,其它结点的平衡因子作相应处理。
B-树
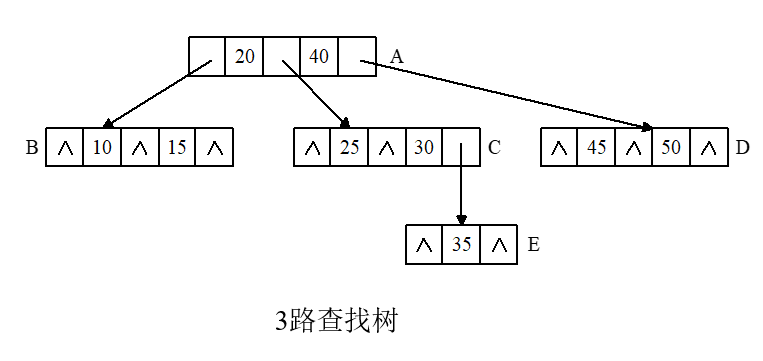
m路查找树
m路查找树是二叉排序树的一个推广,他修改了结点所含成员,一个m路查找树的结点至多含m棵子树和m-1个关键字。其中关键字的排序顺序也是从小到大的顺序。
3路查找树例子
B-树
- B-树就是一棵平衡的m路查找树。在B-树中我们引入“失败”结点,一个失败结点是当所查找的关键字不在树中时才能到达的结点。
- B-树性质:
- 树中每个结点最多有m棵子树;
- 根结点至少有两棵子树;
- 除根结点之外的所有非叶子结点至少有棵子树;
- 所有失败结点出现在同一层上,失败结点为虚结点,在B-树中并不存在, 可视为查找失败时到达的结点,指向它们的指针为空指针。
具体例子:
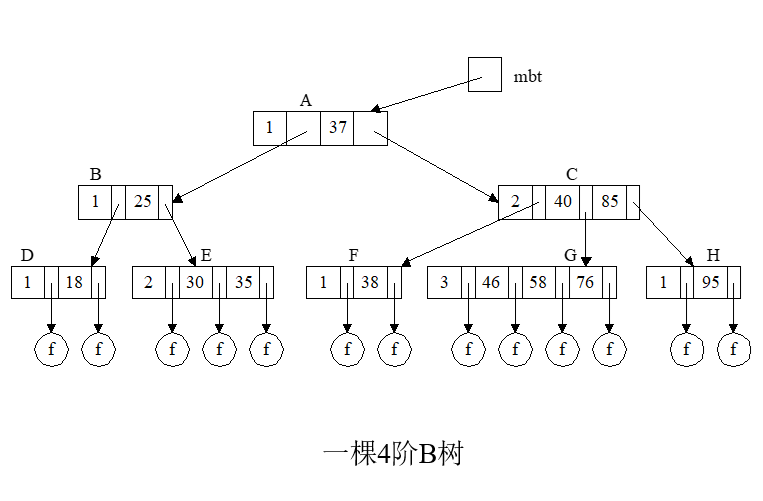
- B-树查找性能分析
B-树的查找时间与B-树的阶数m和B-树的高度h直接有关,必须加以权衡。
B-树的插入
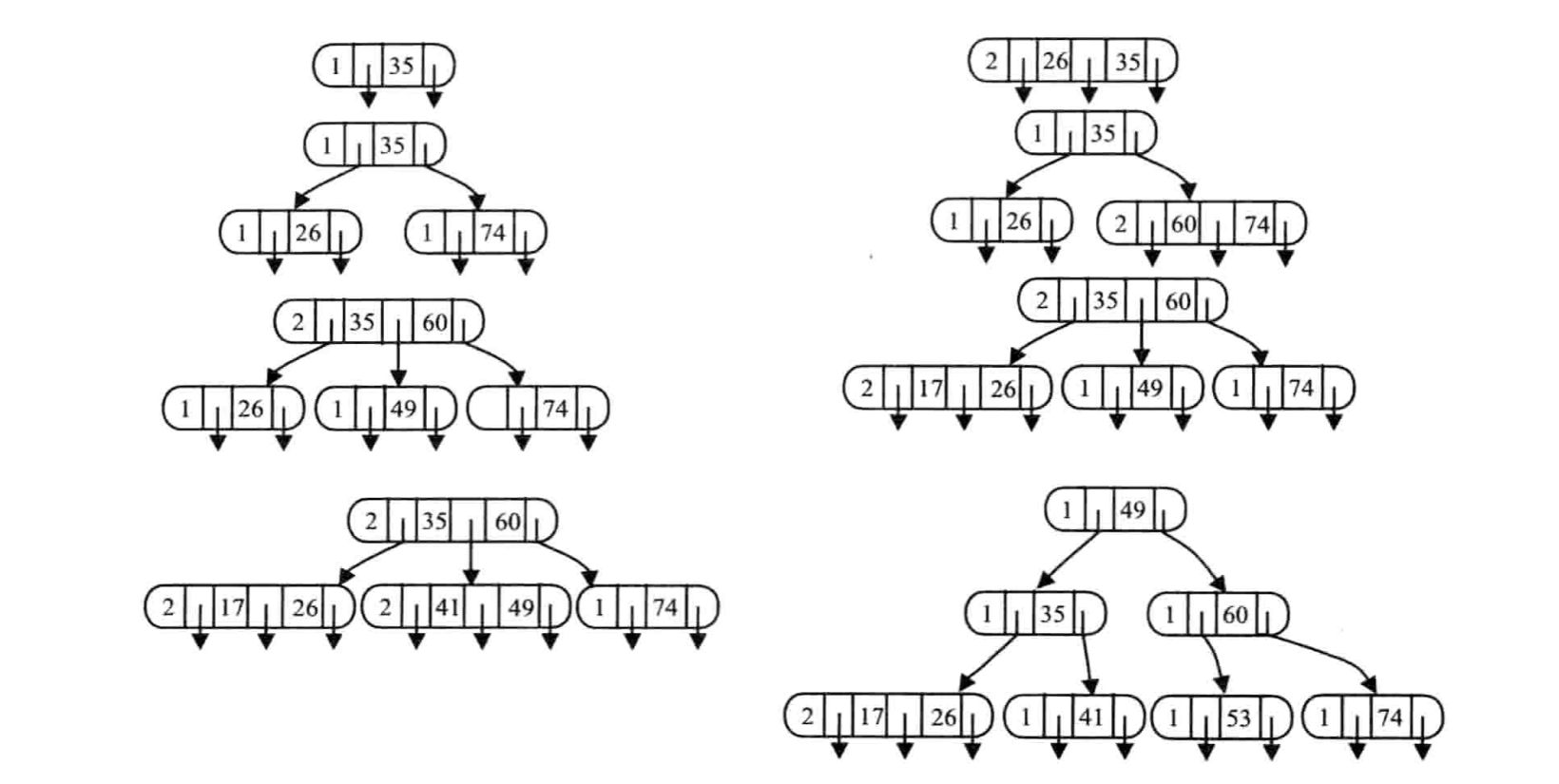
在一棵m阶B-树中,每个非失败结点的关键字个数都在 ~ 之间。如果在关键字插入后结点中的关键字个数未超出上述范围的上界m-1,则可以直接插人;否则结点需要“分裂”。
分裂原则:
- 每一次插入结点一定是在叶子结点上插入,然后再看要不要分裂。具体实践可以看下图的例子
B-树的删除
B-树的删除总体上可以分为两种:删除根节点元素和删除叶子结点元素,其中删除叶子结点元素又分为四种。
删除根节点元素
删除根节点元素只要将该结点的所指子树中的最小关键字(所指子树中的最大关键字k)来代替被删关键字,然后在k所在的叶结点中删除即可。
删除叶子结点元素
删除叶子结点元素分为四种情况
- 被删关键字所在叶结点同时又是根结点且删除前该结点中关键字个数n≥2。
处理方法:直接删去该关键字并将修改后的结点写回磁盘,删除结束。 - 被删关键字所在叶结点不是根结点且删除前该结点中关键字个数。
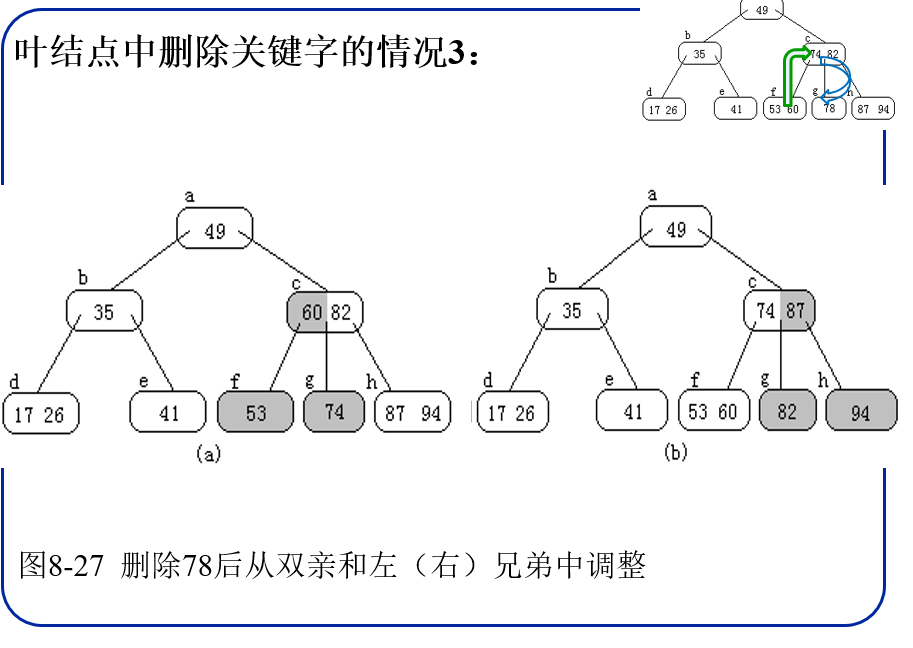
处理方法:直接删去该关键字并将修改后的结点写回磁盘,删除结束。 - 被删关键字所在叶结点删除前关键字个数,与该结点相邻的左(或右)兄弟结点的关键字个数。
处理方法:- 将其双亲结点中大于(或小于)该被删关键字的所有关键字最小(或最大)的一个关键字Ki下移到被删关键字所在结点中;
- 将左(或右)兄弟结点中的最大(或最小)关键字上移到双亲结点的ki位置;
- 将左(或右)兄弟结点中的最右(或最左)子树指针删除,并将结点中的关键字个数减1。
实际图示可以看如下图:
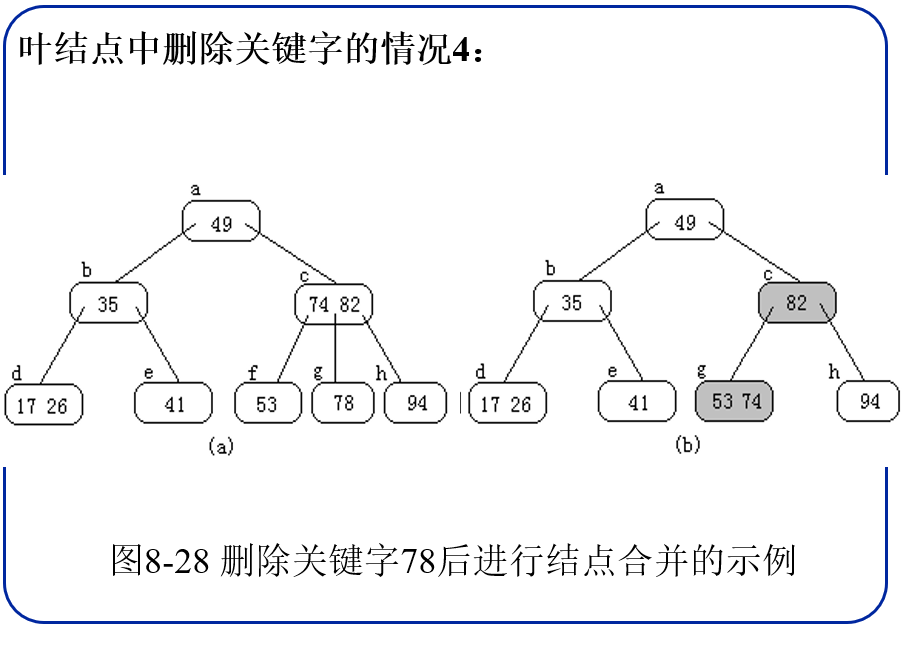
- 被删关键字所在叶结点p删除前关键字个数,与该结点相邻的左、右兄弟结点中的关键字个数也都为。
处理方法:- 将其双亲结点中大于(或小于)该被删关键字的所有关键字最小(或最大)的一个关键字Ki下移到被删关键字所在结点中;
- 将左(或右)兄弟结点中的最大(或最小)关键字上移到双亲结点的ki位置;
- 将左(或右)兄弟结点中的最右(或最左)子树指针删除,并将结点中的关键字个数减1。
B+树
B+树可以看作是B-树的一种变形,在实现文件索引结构方面比B-树使用得更普遍。
- B+树定义
- 树中每个非叶结点最多有m棵子树;
- 根结点至少有2棵子树。除根结点外,其它的非叶结点至少有m/2棵子树;有n棵子树的非叶结点中含有n个关键字,且按由小到大的顺序排列。
- 所有的叶结点都处于同一层次上,包含了全部关键字及指向相应数据元素的指针,且叶结点本身按关键字从小到大顺序链接;
- 所有的非叶结点可以看成是索引部分,结点中关键字Ki与指向子树的指针Pi构成一个索引项(Ki、Pi)。其中Ki是Pi所指向的子树中最大(或最小)的关键字。
-
B+树的查找
B+树有两种查找方式,一种是对叶结点之间的链表进行顺序查找,另一种是从根结点开始,进行自顶向下,直至叶结点的随机查找。 -
B+树的插入
B+树的插人仅在叶结点上进行。每插入一个关键字后都要判断结点中的子树棵数是否超出范围。当插人后结点中的子树棵数n>m时,需要将叶结点分裂为两个结点,它们所包含的关键字个数分别为。并且它们的双亲结点中应同时包含这两个结点的最大关键字和指向这两个结点指针。当根结点分裂时,因为它没有双亲结点,就必须创建新的双亲结点,作为树的新根。这样树的高度就增加一层了。B+树的建立可以从空树开始,通过不断插入关键字完成。 -
B+树的删除
B+树的删除也仅在叶结点中进行。若在叶结点中删除一个关键字后,其关键字的个数仍然不少于,这属于简单删除,其上层索引可以不改变。如果在叶结点中删除一个关键字后,其关键字的个数小于结点关键字的个数的下限,则必须做结点的调整或合并工作。
散列表
散列法查找又称哈希法、杂凑法或关键字地址计算法等,相应的表称为哈希表。 这种方法的基本思想是:首先在元素的关键字k和元素的存储位置p之间建立一个对应关系H,使得p=H(k),H称为散列函数。创建哈希表时,把关键字为k的元素直接存入地址为H(k)的单元;以后当查找关键字为k的元素时,再利用哈希函数计算出该元素的存储位置p=H(k),从而达到按关键字直接存取元素的目的。(通过散列函数构建关键字与内存之间的关系)。
如何构建散列函数
此处介绍一些常见的散列函数
-
直接定址法
优点:不会出现冲突
缺点:散列地址空间的大小与关键字集合的大小相同(比较耗费空间) -
数字分析法
数字分析法就是根据散列表的大小,在关键字中选取某些分布均匀的若干位作为散列地址。
计算均匀度公式: -
除留余数法
-
乘余取整法
避免冲突的方法
这里存在这一个问题:不同的关键字可以对应相同的哈希表,这就是冲突,冲突是无法避免的,只有通过改进哈希函数的性能才能减少冲突。
处理冲突主要有闭散列和开散列两种方法
闭散列
- 闭散列的线性探索法
当需要查找或加入一个元素时,使用散列函数计算以确定元素的桶号:h=Hash(Key)。一旦发生冲突,则依次向后寻找“下一个”空桶Hi的公式为:
直至找到空的位置。
缺点:线性探测方法容易产生“堆积(clusters)”的问题,即数据元素集中占据了数据表的某一区域,使得为寻找某一数据元素需要的查找时间增加。
注意事项:闭散列是不可以直接删去点的,会导致其他元素的查找错误,所以只能设置一个删除标记(浪费空间)
2. 二次探索法
二次探索和线性探索相比结点间隔更远一些。
- 双散列法
两个散列表,发生冲突了使用另一个散列表rehsah。
开散列
闭散列的每一个桶只能含有一个元素,而开散列的每一个同可以含有多个元素,只要通过链式结构就可以实现多元素存储。实例如下:
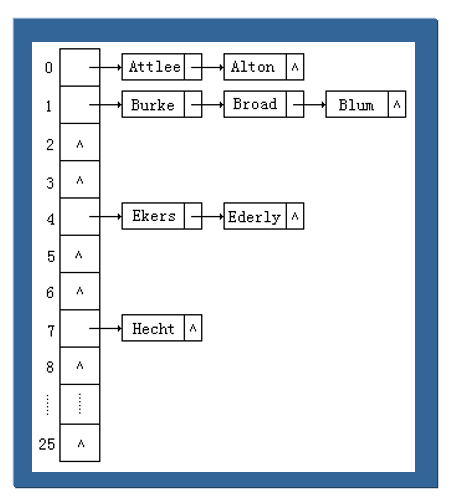
对于一系列冲突解决方法的比较

 wechat
wechat alipay
alipay








